![arxiv:2412.08580v2 [cs.cv] 2024年12月13日](/simg/1/19dd6a46813f915b66aeefb39547498261a82650.webp)
机构名称:
¥ 1.0
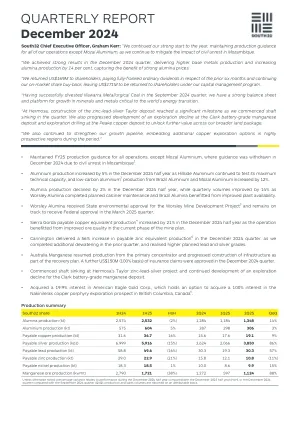
文本对图像(T2i)生成模型[7,9,24,31,33,36,41,59]已取得了显着的进步,展示了从文本提示中生成高质量图像的不断增强的能力。然而,在审查T2i生成模块时,观察到它们通常对于模拟场景生成有效,但在处理复杂场景时显着恶化,例如涉及多个对象及其之间的复杂关系的场景(图1)。我们将此限制归因于对现有文本图像数据集中复杂的对象关联的不足。先前的T2i作品主要集中于建筑改进,这些改进无法解决这一基本问题。场景图(SG)提供了图像内容的结构化描述。场景图由节点(表示对象和属性)和边缘(描述对象之间的关系)组成。与文本的顺序描述相比,SGS提供了紧凑的结构化方法,可以描述复杂的场景,从而提高注释效率。sgs还允许对相关属性及其关系的特定对象进行更精确的规范,这对于生成复杂场景至关重要。但是,存在场景图数据集的规模相对较小(例如,可可粘结[4]和Visual Genome [20]),而大型数据集则主要由文本注释组成。我们的工作重点是通过场景图(SG2CIM)生成组成图像。我们构建了Laion-SG数据集,这是Laion-Asestheics V2(6.5+)[38]的显着扩展,具有高质量,高复杂的场景图表。我们的注释具有多个对象,属性和关系,描述了高视觉质量的图像。因此,我们的Laion-SG更好地封装了复杂场景的语义结构,从而支持改进的复杂场景的发生。Laion-SG在复杂场景生成中的优势在具有多个语义一致性的多个指标的进一步经验中得到了验证。使用Laion-SG,我们训练现有模型,并提出了一个新的基线,用于使用SGS生成复杂的场景。要构建基线,我们使用SDXL [31]作为骨干模型,并训练辅助SG编码器将SG纳入图像生成过程中。具体来说,SG编码器采用图形神经网络(GNN)[37]在图中典型的场景结构,从而优化了SG嵌入。然后将这些嵌入到后骨模型中以产生高质量的复合图像。我们的ap-
arxiv:2412.08580v2 [cs.cv] 2024年12月13日
主要关键词
![arxiv:2412.08580v2 [cs.cv] 2024年12月13日PDF文件第1页](/bimg/d/d4d945e3baf7693543d81118fba282f040d9d3cc.webp)
![arxiv:2412.08580v2 [cs.cv] 2024年12月13日PDF文件第2页](/bimg/3/3e1e39d4cde4d0c5787f277b35d7bfd8cfe5812b.webp)
![arxiv:2412.08580v2 [cs.cv] 2024年12月13日PDF文件第3页](/bimg/c/cb1cc13b10b95d48126876254fea7bb35414e7a3.webp)
![arxiv:2412.08580v2 [cs.cv] 2024年12月13日PDF文件第4页](/bimg/e/e1f7e4d53d17a1aaec454331e91042411b3573a4.webp)
![arxiv:2412.08580v2 [cs.cv] 2024年12月13日PDF文件第5页](/bimg/2/2f77ec265851686248b531fd9a8d8fca011dd4da.webp)
相关文件推荐
![arxiv:2412.05024v1 [cs.ro] 2024年12月6日](/simg/8/87d4fa5715751706d180dd1f0a48fb98bfa72b7d.webp)
![arxiv:2412.14135v1 [cs.ai] 2024年12月18日](/simg/b/ba6858cc5362071828a21c1cb0683c3c2b12b707.webp)
![arxiv:2412.07623v1 [Quant-ph] 2024年12月10日](/simg/2/206d07d0c3d81e24d44a15476c3e76d02bc1858d.webp)
![arxiv:2412.19197v1 [Math.ap] 2024年12月26日](/simg/7/7f2af545e341d1ea82b5aa4511a1d0f05d37869f.webp)
![arxiv:2412.11918v1 [Quant-ph] 2024年12月16日](/simg/e/ed3f2b369bed5135dca7fbf16cfa70d45057deef.webp)


![arxiv:2410.19363v2 [cs.cv] 2024年12月23日](/simg/6/686e38225a84bacafbcd016080a298d9958cd5fd.webp)

![arxiv:2412.04469v1 [CS.CV] 2024年12月5日-NIPS Papers](/simg/d/d2c25b9caa37938f66dbb4fdda58fd675645fcf3.webp)


![arxiv:2402.08540v1 [cs.lg] 2024年2月13日](/simg/0/0d3c5d21d7ebc6c4f9033fdcaf762fcc6af0e990.webp)

![arxiv:2402.08727v1 [Quant-ph] 2024年2月13日](/simg/8/8fe1e629ad084c14b4a994d1dc5f17f112232ca0.webp)